他预计将从AI模型训练转向大规模推理,更广泛地应用自主云运营,以及站点可靠性工程团队面临的压力增加。
中国存储网消息,近日美国初创公司Komodor联合创始人兼首席技术官Itiel Shwartz表示,到2026年,AI负载较重的工作量将颠覆大型组织运行Kubernetes和云基础设施的方式。他预计将从AI模型训练转向大规模推理,更广泛地应用自主云运营,以及站点可靠性工程团队面临的压力增加。
施瓦茨表示,为传统网络和微服务应用构建的基础设施现在面临不同的需求形态。生产中的AI模型需要持续且可预测地访问GPU资源、更高的吞吐量以及更严格的成本控制。这种压力开始在云服务提供商的大型Kubernetes集群中显现。
“随着人工智能/机器学习的持续增长,更多工作量将从培训转向推理。即使是新的GKE实验也显示出这种迹象,因为它们可扩展的节点数量庞大,包含了大量的推理工作负载,“Komodor的首席技术官兼联合创始人Shwartz说。
他表示,此次转型的运营影响首先将落在SRE和平台工程团队身上。许多企业已经运行着大型的Kubernetes资产,并且他们现在在现有集群上叠加AI和生成式AI服务。
人工智能SRE的出现
施瓦茨预计,劳动力短缺和生成式人工智能采用者的竞争压力将推动企业向“人工智能SRE”迈进。这描述了一种小型人类团队与自动化代理和机器学习系统并行管理日常作的模型。
“随着越来越多的组织部署云原生基础设施,以及生成式人工智能缩短竞争对手的上市时间,平台团队将明白,为了持续创新和引领,他们需要扩大SRE团队规模。随着Kubernetes专家的稀缺,AI SRE将成为他们适应的缺失要素,“Shwartz说。
他说,这一转变依赖于标准化的运营数据和集群内明确的控制点。这包括一致的遥测数据、共享事件格式,以及自动化系统能够安全调用的API。
走向自治
Shwartz预计,云运营将逐步从人工自动化向更具自主性的转变。他说,AI辅助工具正在那些此前抗拒自动修复或规模化决策的企业中获得认可。
“随着越来越多的人工智能驱动工具被采用,用户对其信任也越来越高,我们将看到传统保守企业向允许部分运营由AI自主管理的趋势转变,”施瓦茨说。
他建议组织将自动化作包裹在政策即代码和审计追踪中。这种结构将使团队能够在保持治理的同时扩大自动化运营的范围。
新的工作系统
Shwartz强调了复杂工作负载为计算资源排队的方式发生了变化。他预计,随着组织在高性能计算、人工智能和机器学习以及新兴量子工作负载的竞争中,像Kueue这样的云原生作业队列系统将获得更高的采用率。
传统的作业队列是围绕较小或弹性较小的环境构建的。它们往往无法应对现代集群中突发型、以GPU为中心和多租户的现实。Shwartz表示,这一限制为新调度器和队列管理器打开了与Kubernetes更紧密集成的大门。
“云原生的作业队列系统,如Kueue,随着HPC、AI/ML甚至量子应用的部署竞赛加剧,采用率将大幅提升。由于以往的排队系统并非为如此规模打造,新的工具将迅速在行业内实施,“Shwartz说。
调度器大改
Shwartz表示,Kubernetes调度器本身在这些条件下也面临重大变化。当前设计强调以舱体为主要调度单元。AI训练和推理工作负载通常需要多个Pod组一起启动,并共享GPU和网络资源。
他指出社区正在进行的“帮派排班”工作,即将一组任务视为一个可排班的单元。该功能出现在 Kubernetes 增强提案 4671 中,目标是在未来版本中实现原生支持。
“随着应用和工作负载比以往更多的计算需求,Kubernetes 调度将需要彻底革新。目前以播客为中心的方法无法应对这种增加的规模,因此调度器需要更针对工作负载的具体处理方式。社区正在通过KEP-4671:帮派调度积极开展这项工作,该项目将由K8s原生管理,“Shwartz说。
GPU压力
AI推理的扩展也将注意力集中在GPU容量和成本上。Shwartz预计,随着组织寻求集群间更高的利用率,GPU过度配置将成为更明显的运营问题。
“随着宏观经济环境持续推动更高效率,组织必须找到优化GPU监控和使用的方法,”Shwartz说。
他建议平台团队将GPU效率视为可靠性问题,而不仅仅是支出问题。这包括围绕GPU使用量设定服务水平目标,追踪碎片化和饱和度,并将这些指标输入自动扩展器和准入控制。
工具整合
Shwartz还预测云基础设施工具将会被整合。他将云安全类比,后者已远离多点产品。
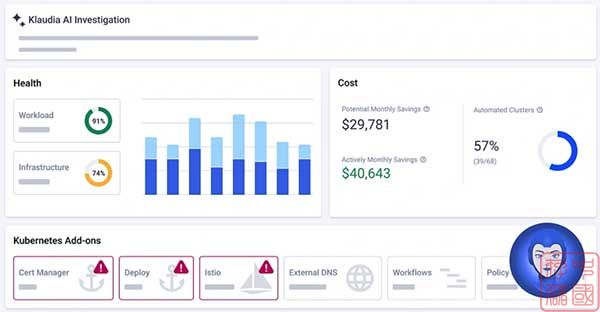
“FinOps工具将开始与云基础设施堆栈中的其他产品整合。类似于云安全领域正在发生的事情,产品将整合包括可观察性、洞察、追踪、成本优化和故障排除等不同能力,整合到一个平台上。这将减轻团队难以应对过多仪表盘和产品的认知负担,“Shwartz说。
他说,平台领导者应从审查现有工具链开始,识别监控、追踪、成本分析和调试的重叠。该评估将为兼顾运营健康与财务效率的综合系统奠定基础。
Shwartz表示,随着AI工作负载在2026年Kubernetes资产层的扩展,平台团队能够更好地实现遥测标准化、尝试新的调度方法并将GPU效率融入SRE实践。
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。