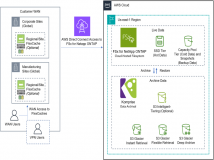
国际知名杂志上新发布的5篇关于DNA存储技术方面的研发创新文章。
研发:高度安全的体内DNA数据存储,由基因组动力学驱动
ICBP通过结合计算逻辑与生物系统的复杂性,提供了一种变革性的安全DNA数据存储策略
《先进科学》发表了徐嘉欣、肺重症医学系、基础医学博士后科研站、深圳呼吸疾病重点实验室、深圳呼吸疾病临床研究中心、深圳呼吸疾病研究所、深圳人民医院(济南第二临床医学院)的文章中国广东省深圳南方理工大学第一附属医院大学,以及中国广东省广州济南大学药学院、中国科学院深圳高中技术研究院余王大学,以及 深圳合成基因组学重点实验室、广东省合成基因组学重点实验室、深圳合成生物学研究所定量合成生物学重点实验室、中国广东济南大学药学院海博周、中国科学院深圳高级技术研究院李明根深圳合成基因组学重点实验室、广东省合成基因组学重点实验室、定量合成生物学重点实验室、深圳合成生物学研究所、中国科学院杨旺、肺重症医学系王玲伟、基础医学博士后科研站、深圳呼吸疾病重点实验室, 深圳呼吸疾病临床研究中心、深圳呼吸疾病研究所、深圳人民医院(济南大学第二临床医学院,南方理工大学第一附属医院)、中国广东、惠美、中国科学 院深圳高中高中研究院、深圳合成基因组学重点实验室、广东省合成基因组学重点实验室、定量合成生物学重点实验室、中国深圳合成生物学研究所、戴君彪、中国科学院深圳先进技术研究院、中国深圳 ,深圳合成基因组学重点实验室、广东省合成基因组学重点实验室、定量合成生物学重点实验室、深圳合成生物学研究所、深圳分院、岭南现代农业广东实验室、农业农村部基因组分析实验室、深圳农业基因组学研究所、中国农业科学院、深圳, 中国,陈珊哲,肺与重症医学系,基础医学博士后科研站,深圳呼吸疾病重点实验室,深圳呼吸疾病临床研究中心,深圳呼吸疾病研究所,深圳人民医院,(济南大学第二临床医学院,南方理工大学第一附属医院), 中国广东省深圳市,以及中国科学院深圳高中技术研究所黄晓洛,以及深圳合成基因组学重点实验室、广东省合成基因组学重点实验室、定量合成生物学重点实验室、深圳合成生物学研究所。
摘要:“DNA因其超高信息密度和稳定性,是下一代数据存储的有前景媒介。DNA在生物体内的储存还带来了额外的优势,如自我复制、紧凑性和隐蔽性。早期工作主要开发了利用体内DNA序列编码和解码数据的预定方法。然而,这些方法可能存在安全风险,同时为潜在的数据访问和泄露打开了清晰的渠道。为应对这些挑战,我们提出了一种统一范式——集成计算-生物编程(ICBP),利用计算和微生物系统内在的数字特性。ICBP涉及从基因调控网络或跨物种的完整基因组构建动态编码表,使关键空间比现有方法扩展了100多个数量级。ICBP中的加密算法受益于DNA编码、计算和计算作,从而实现了更优越的加密质量和对暴力破解和统计攻击的抵抗力。此外,我们通过成功加密、微生物存储和解密活体系统中的数字文件,展示了ICBP的实际效用,实现了100代复制后的100%数据恢复。通过将计算逻辑与生物系统的复杂性结合,ICBP为安全DNA数据存储提供了一种变革性的战略。”
研发:高数据密度、高速解码、高精度DNA数据墨水数字保存技术
奠定了适用于文化遗产保护、自动驾驶车辆数据管理和基于矩阵机器学习应用的实用DNA数据存储解决方案基础
ACS Nano发表了一篇由大韩民国仁川国立大学纳米生物工程系林道妍撰写的文章,作者为119 Academy-ro,仁川大学智能半导体工程系,仁川国立大学119学院路,2012,韩国仁川大学,119 Kim,纳米生物工程系,119韩国仁川学院路22012,加州大学圣地亚哥分校生物工程系Xiaohua Huang,9500 Gilman Drive, La Jolla, 美国,美国,Kim晋哲,韩国生物科学与生物技术研究院老龄研究中心,大田34141,韩国,以及宋永俊大韩民国仁川国立大学纳米生物工程系,119 Academy-ro 仁川 22012,韩国仁川国立大学智能半导体工程系,119 Academy-ro in cheon 22012,以及标准生物电子公司,511 Michuhol Tower Hall Tower Gaetbeol-ro 12, 仁川 21999,韩国。
摘要:“基于DNA的存储相比传统数字媒体提供了卓越的信息密度、耐用性和能效,但实际实施面临诸如高合成成本、测序错误和访问速度缓慢等挑战。本文介绍了一套集成DNA存储系统,采用优化编码和处理策略,以解决实际实现问题。我们的方法实现了9.78比特/nt的净信息密度,采用灵活的索引分配系统处理数据量,范围从0.37 KB到2.79 ×10 22 YB。该解码过程比传统方法快360×,34.5秒处理457万次读取(1.63GB),并展示了从下采样(×5.33)测序中2.47秒内完美检索数据。我们的纠错系统结合了内部Reed-Solomon和外部XOR码,确保了在大读数序列(92,626)和低拷贝数数据(×0.52)下实现的可靠恢复。简化的NGS制备流程将处理时间从约4.5小时缩短至约2小时,同时将每个样品的成本从约60美元降至约0.50美元。该系统通过高精度DNA数据存储墨水以及从实体邮票到虚拟现实平台的多种实现,展示了其多功能性。该技术为适用于文化遗产保护、自动驾驶车辆数据管理和基于矩阵的机器学习应用奠定了实用的DNA数据存储解决方案基础。“
研究与发展:关于基于频率的噪声信道的容量
作者研究基于低分子区域DNA数据存储的低频信道容量,该区域信息编码于项目类型的频率而非顺序
arXiv 发表了一篇由以色列理工学院的尤瓦尔·格尔宗、美国伊利诺伊大学厄巴纳-香槟分校的伊兰·肖莫罗尼和以色列理工学院的尼尔·温伯格撰写的文章
摘要:“我们研究基于频率的噪声通道的能力,这受短分子区域DNA数据存储的动机,该区域信息通过项目类型的频率而非顺序编码。信道输出是一个直方图,由随机抽样项目形成,随后进行噪声项目识别。虽然此前已研究过无噪声基于频率的信道容量,但识别噪声的影响尚未被完全表征。我们提出了一个由随机退化和数据处理不等式推导出的通道容量的反上界。然后我们建立一个可实现的界限,该界限基于对多项采样过程的泊松化,以及对所得向量泊松通道的符号间干涉的分析。该分析细化了费因斯坦束缚中信息密度的浓度不等式,并明确表征了由识别噪声引起的互信息加法损失。我们将研究结果应用于短分子区的DNA存储通道,并量化了可靠存储比特总数的缩放损失。”
研发与开发:为总信道设计的纠错码
作者介绍了总信道,这是一种受分布式存储和DNA数据存储应用启发的新信道模型
arXiv发表了一篇由以色列理工学院计算机科学系的Lyan Abboud和Eitan Yaakobi撰写的文章,他们位于以色列海法。
摘要:“我们介绍了sum channel,这是一种受分布式存储和DNA数据存储应用启发的新通道模型。在无错误情况下,它以 ell 行二进制矩阵为输入,输出一个 (ell+1) 行矩阵,其前 ell 行等于输入,最后一行为奇偶校验(和)行。我们构造了一个双删除校正码,冗余为 2lceillog_2log_2 nrceil + O(ell^2),用于 ell-row 输入。当 ell=2 时,我们建立 lceillog_2log_2 nrceil + O(1) 的上界,这意味着我们的冗余在 2 倍内是最优的。我们还给出了一条用lceil log_2(ell+1)rceil冗余位修正单次替换的代码,并证明其最优位在一位以内。”
研发:快速引导和可靠读取,利用隐藏引用进行DNA数据存储
作者提出了一个快速可靠的读取框架,采用引导方式,专为使用水印大型DNA片段的数据存储量身定制
iMeta发表了一篇由陈伟刚撰写的文章,作者是天津大学微电子学院,天津大学合成生物学国家重点实验室,天津,中国天津,中国。天津大学合成生物学与生物制造学院(教育部)前沿科学中心,天津大学,刘双、全郭、瑞琴、齐歌、婷婷齐,天津大学微电子学院 ,天津大学国家重点合成生物学实验室,天津,中国天津,中国,以及 中国天津大学合成生物学与生物制造学院(教育部)前沿科学中心。
摘要:“利用大DNA片段进行数据存储实现了低成本的体内复制,并为分布式数据应用提供了有前景的策略。然而,大规模无序测序读取的数据需要基于重叠区域进行比对,且因多种测序错误,尤其是插入和删除(indel)错误而复杂化。本文提出一个快速可靠的自导式读取框架,专为使用水印大DNA片段的数据存储量身定制。我们的方案通过多重隐藏引用将全新读出转变为类似重序的工作流程,大幅降低读出复杂度。该框架兼容具有不同错误谱性的测序平台。对于插入率较低的技术,我们采用基于相关性的识别和按位共识实现快速解码。对于易入的平台,我们采用多重隐藏引用和前后算法的渐进式读取对齐,以确保稳健的恢复。对具有不同编码效率的大型DNA片段进行的体内实验验证了该框架。使用Illumina读段(原始错误率~0.2%),覆盖率为0.6–2.5×以及纳米孔读段(原始错误率~5%),覆盖率为1.6×或4.3×实现了无错误恢复。这些结果展示了大片段DNA存储在现实应用中的实用性和可扩展性。”
声明: 此文观点不代表本站立场;转载须要保留原文链接;版权疑问请联系我们。